Scientific and Philosophical Questions, Links
This last part of my strategy game programming tutorial focuses on some questions which turned up during my programming sessions. Many of them have no clear answers, but are just some observations I made along the way. I find them interesting - I hope you do too.- The need for speed
- Smart and slow or dumb and fast?
- Machine learning
- Improving your program
- Other sites on strategy game programming
The need for speed
Game programmers are obsessive about the speed of their programs. Many would sell the soul of their first-born child for another 10% speed increase. Why is this? The reason for this craze over a few % is that it does make a difference. In fact, it makes a larger difference than you might think. In a famous experiment, Ken Thompson found that his chess program "Belle" gained 200 elo points (a measure of playing strength) for every additional ply it searched. It means get an average of 75% of the points when you play an opponent with 200 points less. Everybody tried this experiment, and everybody found the same result. So people started speculating how many ply you need to be world champion. They also started speculating about "diminishing returns": the notion that once you have a certain search depth, you will not gain much more by searching another ply. This diminishing returns thing has been looked for in chess, but it proved to be harder to find than expected. I looked for this effect with an old version of my checkers program, Cake++, probably in about the year 2000 or 2001: I used fixed-depth versions of Cake++ which searched to a specific number of plies ahead, 5,7,9, and so on, and always let two versions with a 2 ply difference play each other. I just repeated this experiment (August 2006) with my latest version of Cake (Cake Manchester 1.09d) with the 8-piece endgame database. In my old experiment, Cake++ was only using the 6-piece database. I have plotted the winning percentage of the deeper-searching engine vs its search depth for Chinook, Cake++ and Cake Manchester in the following graph.The Chinook data is probably taken from A Re-examination of Brute-force Search, Jonathan Schaeffer, Paul Lu, Duane Szafron and Robert Lake, Games: Planning and Learning, AAAI 1993 Fall Symposium, Report FS9302, pages 51-58.
Unfortunately, I can't open this PostScript document any more and therefore I can't check whether I took the data from that paper. I wonder if it's just my PC or if it is corrupted?
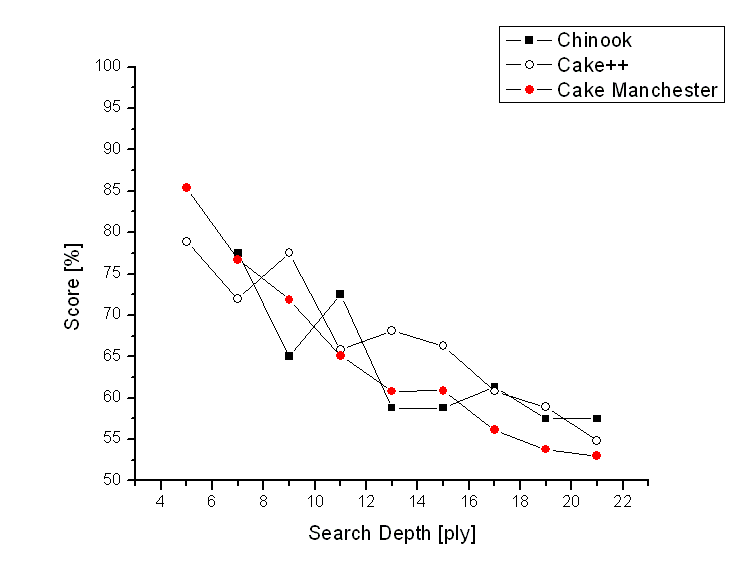
Another thing which I find interesting is that the winning percentage of the deeper-searching Cake Manchester is consistently lower than for Cake++ (with the exception of the first two data points for 5-3 and 7-5 ply). I believe this effect can be explained easily: Cake Manchester is much stronger than Cake++ was. One might argue that Cake Manchester searching 13 ply ahead is about as good as Cake++ searching 17 ply ahead. 13 and 17 are just arbitrary guesses, but in any case it is true that Cake Manchester searching D ply ahead is about as strong as Cake++ searching D+X ply ahead, with X>0. In this sense, the entire curve in the graph is shifted; to use the numbers before, the 13-11 data point for Cake Manchester would be similar to the 17-15 data point of Cake++. Another way to look at this is to not only look at the winning percentage, but at the match result in terms of wins, draws and losses. At the same search depth, there are many more draws in the Cake Manchester match, because this engine is playing much better.
| Search Depth | Cake++ | CakeManchester |
| 5-3 | +196=53-33 | +220=52-16 |
| 7-5 | +153=100-29 | +174=94-20 |
| 9-7 | +181=75-26 | +150=112-25 |
| 11-9 | +130=111-41 | +105=165-18 |
| 13-11 | +134=116-32 | +85=180-23 |
| 15-13 | +119=136-27 | +81=189-18 |
| 17-15 | +89=165-28 | +46=231-11 |
| 19-17 | +78=176-28 | +36=238-14 |
| 21-19 | +60=189-33 | +25=255-8 |
Dumb and fast or smart and slow?
A related question to the diminishing returns thing is this: can a program compensate for missing knowledge by speed? Again, there is a classic experiment by Hans Berliner on this topic, who used his chess program Hitech to answer this question. He crippled Hitech by disabling large parts of the evaluation function, and produced a program called Lotech in this way. Now, he played Lotech against Hitech, giving Lotech the advantage of searching one ply deeper. The surprising result is that Lotech won consistently against Hitech. Again, people think that there should be a "crossover point", where the Hitech version of a program should beat the Lotech version. And again, in computer chess, it proved hard to find. I also looked for this with my checkers program, but at the time (again with Cake++ about 2001), I also found that Lotech-Cake would consistently beat Hitech-Cake.Machine learning
Machine learning is a fascinating topic. There are many different ways in which computer programs try to make use from past experience, and many of them are called "learning" by the program authors. Let's take a look: The most popular "learning" is rote learning: Your program plays a game, loses the game, and remembers it lost this game. This can be implemented as book learning, where your program will flag a book move as bad, if it loses a game with it and chooses another move next time round. Or it can be implemented in the form of a small hashtable, where positions from games it lost are stored as lost. Like this, the program will not play into this position again. But: this form of learning is very specific. It is too specific! Your checkers program might know that one specific position is bad. But what if a whole class of positions is to blame which your program does not understand? In checkers, there are the famous "holds". In such a situation, e.g. 3 checkers of yours are held by 2 of your opponent. Regardless of what the rest of the situation is on the board, (more or less) he will win, because it's like being a checker up. Your basic rote learning program will see that one position with this hold is lost - but there are millions of others like it! And it will play the same game again, varying slightly only to find itself lost again. This type of learning is no real learning and I consider it pure hype to call such programs "intelligent" or "learning from mistakes".Another type of machine learning uses automated evaluation weight adjustment. This is the domain of genetic algorithms: genetic algorithms make use of evolution theory found in nature to find the "fittest" program. Here's how it works: You produce a (typically linear) evaluation function, where every term has a weight, that is:
eval = w_1*f_1 + w_2*f_2 + ... + w_n*f_n
the f_i are features of the position. Example: in checkers, you could define f_1 as black has a strong back rank. Now, the larger w_1 is, the more your program will try to keep it's back rank intact. So once you have selected your set of features, you go ahead and try to optimize the weights. The genetic approach does this by selecting a number of programs with initial weights at random, and then lets them play each other to find which ones are good and which are bad. A number of the bad programs gets zapped, and the fit programs survive and breed offspring - either by generating a cross of two succesful programs (taking each w_i at random from two fit programs), or by random mutation of a single fit program. Now you just continue this process, and hope that you get a really good set of weights in the end. This is approximately the approach Arthur Samuel took in his famous checkers program in the 1950's. There are other types of weight fitting: the Deep Blue team used a huge set of positions from grandmaster games, and let the program crunch on them. They measured the number of times the program chose the same move as the grandmaster. Then they varied the weights, and tried again. If it solved more positions, they kept the changes, else they discarded them. The last weight-fitting approach I know of was used by Michael Buro in his world champion Othello program, Logistello. He used a huge database of positions, which were scored according to the result of the game. Then, he used his evaluation function on all these positions to optimize it to reproduce the scores as well as possible.
All of these approaches are already much a better form of learning than rote learning. Here, if a program has a feature for such a hold in checkers, you will find that increasing the weight of this term in the evaluation will really make the program know that a whole class of positions is bad, and it will avoid them. So here, do we have learning? I say no! What if this feature had never been in the program? It could have adjusted weights as long as it wanted to, and it would never have gotten anywhere. Therefore, we get to the next step in learning:
Neural Networks can "invent" patterns that nobody has told them of. NNs can be used to make an evaluation of board positions and be incorportated into a normal game playing program. NNs consist of a number of inputs, some optional hidden layers, and an output. The layers connecting the inputs and the output are again a number of nodes which have input connections from the layer before, and output connections to the next layer. A node can have any number of connections to the other layers. Each connection can be stronger or weaker. By simultaneously changing the connections and their strenghts, you can do both pattern recognition and have a weight to each pattern.
NNs can be trained by giving them scored test positions, or they can even learn everything by themselves, by combining the NN with a genetic approach to find the fittest NN. Blondie24, a checkers program, uses this very approach, and it learned to play checkers relatively well, all by itself! This, to me, is true learning. It is similar to the way humans think. The authors of Blondie claim a bit more about it than what is true, but unfortunately that is true for most researchers today - you need to produce lots of publicity to get funding...
Improving your program
You spent countless hours writing your program, and now it plays like a beginner? That is more common than the opposite, but don't despair: I have a number of tips for you! First and foremost: the most problems arise because of bugs in your code. The AlphaBeta algorithm has the insidious property of hiding bugs: for a million positions evaluated in your program, all you get is one move. Even if you return random numbers for 10% of your evaluations, your program will still play decently most of the time. Therefore, you need to take some extra measures to be sure everything is working ok. One typical example is a test of your evaluation symmetry: If your eval doesn't return the same number for a position and the color-reversed twin, then something is wrong. If your board has other symmetries (in chess you have a mirror operation through the middle half of the board between d- and e-file), you can use these too. Try writing as clear code as possible - don't optimize too early, it isn't worth while. Don't add all bells and whistles to your program before it plays its first regular game on a plain alphabeta algorithm. Once you have eradicated your bugs, you will want to start tuning it. Is it too slow? You can use profilers such as AMD's CodeAnalyst to find the hotspots in your program and work on them. A very useful tool to improve a program is to have it play against other programs. Play matches with hundreds of games, anything else is not statistically significant. Change something in your code (in your search, in your eval), and replay the matches to confirm your changes are good. If you only changed something in the move ordering, use a test suite instead of a long match, it takes much less time and tells you just as well whether your new move ordering is an improvement or not.Other sites on strategy game programming
- Arthur Samuel
- A book on reinforcement learning
- Neural Networks
- Self-play experiments (Hitech-Lotech, Belle, others)
- Bruce Moreland's pages on chess programming
- Ed Schröder's pages on chess programming
- Digenetics website (Blondie24)
Comments and questions are welcome!
Last update: August 13, 2006, using 